看代码过程中整理的一张思维导图,对理解整个流程有帮助。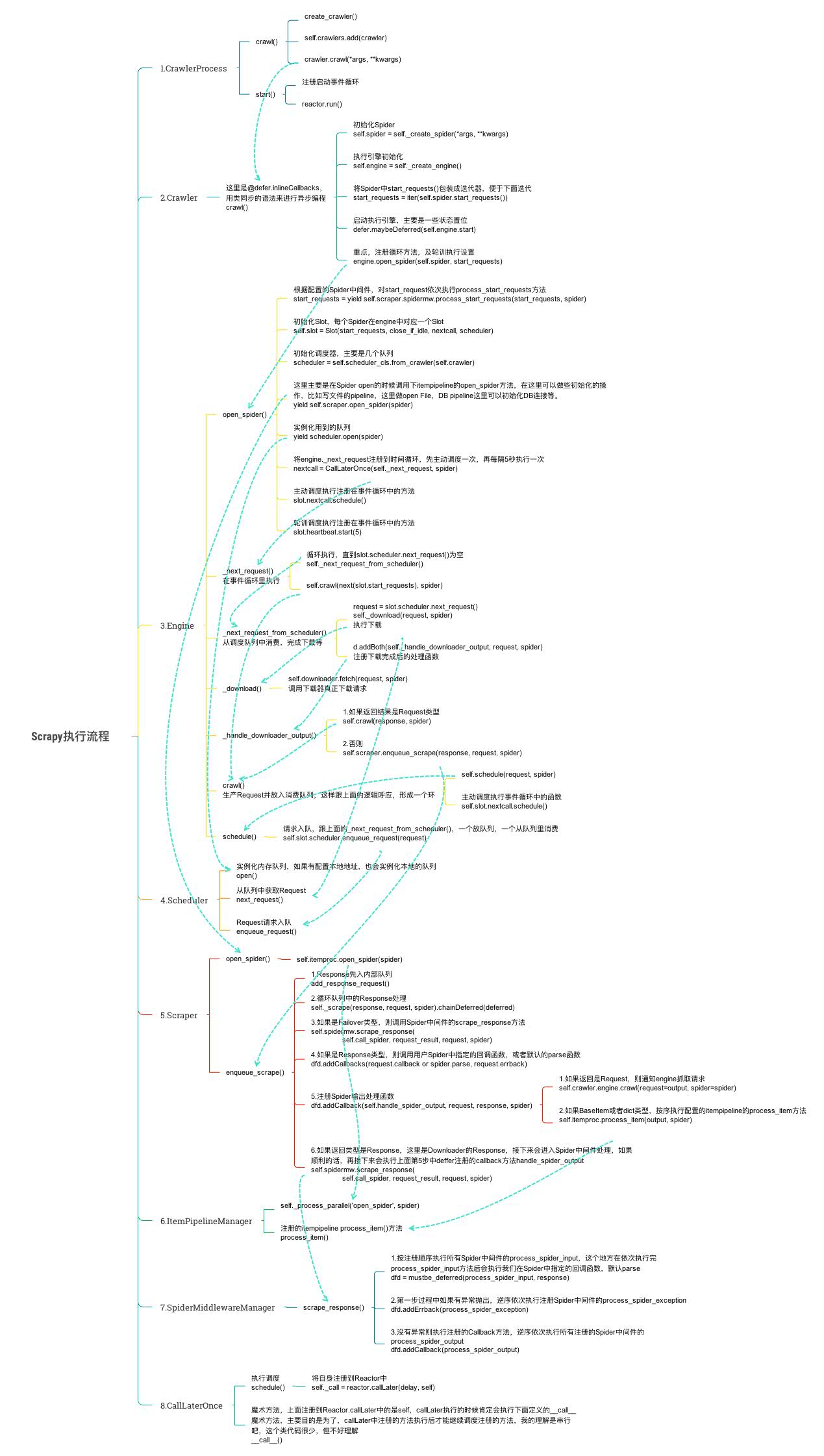
从启动示例说起:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15import scrapy
from scrapy.crawler import CrawlerProcess
class MySpider1(scrapy.Spider):
# Your first spider definition
...
class MySpider2(scrapy.Spider):
# Your second spider definition
...
process = CrawlerProcess()
process.crawl(MySpider1)
process.crawl(MySpider2)
process.start() # the script will block here until all crawling jobs are finished
这是官方推荐的在一个进程启动多个Spider的示例;先实例化一个CrawlerProcess实例,这个就是一个Scrapy进程,接着添加两个Spider,并且启动进程,看起来很简单,下面结合源代码分析Scrapy是怎么完成抓取的。
CrawlerProcess继承自CrawlerRunner,上面示例中CrawlerProcess实例化后,调用crawl方法添加Spider,看看具体代码执行了什么?1
2
3
4
5
6
7
8
9
10
11
12def crawl(self, crawler_or_spidercls, *args, **kwargs):
crawler = self.create_crawler(crawler_or_spidercls)
return self._crawl(crawler, *args, **kwargs)
def _crawl(self, crawler, *args, **kwargs):
self.crawlers.add(crawler)
d = crawler.crawl(*args, **kwargs)
self._active.add(d)
def _done(result):
self.crawlers.discard(crawler)
self._active.discard(d)
return result
return d.addBoth(_done)
可以看出这里是用参数Spider创建了个crawler,并且调用crawler的crawl方面。顺藤摸瓜看看Crawler.crawl()方法到底干了什么?1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19@defer.inlineCallbacks
def crawl(self, *args, **kwargs):
assert not self.crawling, "Crawling already taking place"
self.crawling = True
try:
self.spider = self._create_spider(*args, **kwargs)
self.engine = self._create_engine()
start_requests = iter(self.spider.start_requests())
yield self.engine.open_spider(self.spider, start_requests)
yield defer.maybeDeferred(self.engine.start)
except Exception:
if six.PY2:
exc_info = sys.exc_info()
self.crawling = False
if self.engine is not None:
yield self.engine.close()
if six.PY2:
six.reraise(*exc_info)
raise
这里创建Spider,创建engine。接着调用engine.open_spider(),engine.start(),这个流程先打住,待会回过头来再接下来分析这里。先看下示例代码最后一步process.start()。1
2
3
4
5
6
7
8
9
10
11
12def start(self, stop_after_crawl=True):
if stop_after_crawl:
d = self.join()
# Don't start the reactor if the deferreds are already fired
if d.called:
return
d.addBoth(self._stop_reactor)
reactor.installResolver(self._get_dns_resolver())
tp = reactor.getThreadPool()
tp.adjustPoolsize(maxthreads=self.settings.getint('REACTOR_THREADPOOL_MAXSIZE'))
reactor.addSystemEventTrigger('before', 'shutdown', self.stop)
reactor.run(installSignalHandlers=False) # blocking call
这里引入了Twisted的事件循环并启动,之后上面的engine会注册相关的方法到事件循环中执行。接着上面engine分析。看看open_spider()干了什么?start()很简单,这里不介绍。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17@defer.inlineCallbacks
def open_spider(self, spider, start_requests=(), close_if_idle=True):
assert self.has_capacity(), "No free spider slot when opening %r" % \
spider.name
logger.info("Spider opened", extra={'spider': spider})
nextcall = CallLaterOnce(self._next_request, spider)
scheduler = self.scheduler_cls.from_crawler(self.crawler)
start_requests = yield self.scraper.spidermw.process_start_requests(start_requests, spider)
slot = Slot(start_requests, close_if_idle, nextcall, scheduler)
self.slot = slot
self.spider = spider
yield scheduler.open(spider)
yield self.scraper.open_spider(spider)
self.crawler.stats.open_spider(spider)
yield self.signals.send_catch_log_deferred(signals.spider_opened, spider=spider)
slot.nextcall.schedule()
slot.heartbeat.start(5)
这里创建调度器Scheduler,并调用Spider中间件管理器注册的中间件的process_start_requests对start_requests做相应处理。重点是nextcall,这个就是向上面主流程中的事件循环中注册事件的。从中可以看出把_next_request方法注册到时间循环,并且没5秒钟执行一次。并且这个nextcall也是可以主动调度的。
接着分析engine._next_request()的实现:
1 | def _next_request_from_scheduler(self, spider): |
先从调度器中获取一个请求,执行下载,这中间要经过下载中间件层层过滤。接着注册回调函数_handle_downloader_output方法处理下载后的结果。
看看_handle_downloader_output做了什么:1
2
3
4
5
6
7
8
9
10
11def _handle_downloader_output(self, response, request, spider):
assert isinstance(response, (Request, Response, Failure)), response
if isinstance(response, Request):
self.crawl(response, spider)
return
# response is a Response or Failure
d = self.scraper.enqueue_scrape(response, request, spider)
d.addErrback(lambda f: logger.error('Error while enqueuing downloader output',
exc_info=failure_to_exc_info(f),
extra={'spider': spider}))
return d
如果返回结果是Request类型,需要重新调用crawl()方法,具体做法是,先交给调度器调度。如果返回类型是Response或者Failure,则交给scraper处理。接着看看enqueue_scrape()干了啥?1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16def enqueue_scrape(self, response, request, spider):
slot = self.slot
dfd = slot.add_response_request(response, request)
def finish_scraping(_):
slot.finish_response(response, request)
self._check_if_closing(spider, slot)
self._scrape_next(spider, slot)
return _
dfd.addBoth(finish_scraping)
dfd.addErrback(
lambda f: logger.error('Scraper bug processing %(request)s',
{'request': request},
exc_info=failure_to_exc_info(f),
extra={'spider': spider}))
self._scrape_next(spider, slot)
return dfd
在scraper内部也会维护一个队列,其中add_response_request就是队列的producer,往队列里放任务,_scrape_next则是队列consumer,消费队列的任务。看看如何消费?1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18def _scrape(self, response, request, spider):
"""Handle the downloaded response or failure through the spider
callback/errback"""
assert isinstance(response, (Response, Failure))
dfd = self._scrape2(response, request, spider) # returns spiders processed output
dfd.addErrback(self.handle_spider_error, request, response, spider)
dfd.addCallback(self.handle_spider_output, request, response, spider)
return dfd
def _scrape2(self, request_result, request, spider):
if not isinstance(request_result, Failure):
return self.spidermw.scrape_response(
self.call_spider, request_result, request, spider)
else:
# FIXME: don't ignore errors in spider middleware
dfd = self.call_spider(request_result, request, spider)
return dfd.addErrback(
self._log_download_errors, request_result, request, spider)
如果是Response类型,在执行Spider中间件的scrape_response方法,并注册Spider结果处理函数handle_spider_output();看看handle_spider_output干了些什么?1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23def handle_spider_output(self, result, request, response, spider):
if not result:
return defer_succeed(None)
it = iter_errback(result, self.handle_spider_error, request, response, spider)
dfd = parallel(it, self.concurrent_items,
self._process_spidermw_output, request, response, spider)
return dfd
def _process_spidermw_output(self, output, request, response, spider):
if isinstance(output, Request):
self.crawler.engine.crawl(request=output, spider=spider)
elif isinstance(output, (BaseItem, dict)):
self.slot.itemproc_size += 1
dfd = self.itemproc.process_item(output, spider)
dfd.addBoth(self._itemproc_finished, output, response, spider)
return dfd
elif output is None:
pass
else:
typename = type(output).__name__
logger.error('Spider must return Request, BaseItem, dict or None, '
'got %(typename)r in %(request)s',
{'request': request, 'typename': typename},
extra={'spider': spider})
首先在deffer中注册_process_spidermw_output方法,在_process_spidermw_output的处理中,如果接收到的结果是Request,就通知engine抓取此请求。如果接收到的是BaseItem或者dict类型的数据,则调用配置的itempipeline的process_item方法,这里往往是数据存DB或者写文件中,到此整理流程也就完成了。这只是正常流程的大概描述,中间还有很多异常处理和状态监控、log等等。
