原文:http://tutorials.jenkov.com/java-concurrency/java-memory-model.html
Java内存模型规定了Java虚拟机如何使用物理内存,Java虚拟机是整个计算机模型,当然也包括内存,所以内存的管理称作内存模型。
如果你要正确的编写并发程序,那么理解Java内存模型是非常重要的。Java内存模型规定了多线程间如何以及何时读取和写入共享变量,并且规定怎样同步进入共享变量。
Java 1.5之前的内存模型不太完善,所以Java1.5对内存模型进行了修订,这个版本的内存模型在Java8中依然在使用。
一、内存模型内部结构
JVM内部将内存分为堆和栈两部分,下图从逻辑上说明Java内存模型:
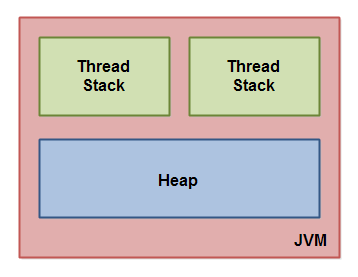
在JVM中,每个线程都有自己独有的线程栈。线程栈包括方法调用以及方法执行上下文信息,这里称它为调用栈,随着方法调用,调用栈不断变化。
调用栈保存了每个方法执行的本地变量,线程只能进入自己独有的线程栈中,并且本地变量对其他线程不可见,两个线程调用同一个方法将分别在他们各自的线程栈中创建本地变量,所以,每个线程都有自己独有的本地变量。
原始类型 ( boolean, byte, short, char, int, long, float, double)的本地变量都完整的保存在各自的线程栈中,并且对其他线程不可见。线程可以传递原始类型的本地变量的副本给其他线程,但不能共享本地变量本身给其他线程。
Java应用创建的所有对象都存储在堆中,包括原始类型的封装类(例如 Byte、Integer、Long等等)。不管对象是作为本地变量被创建,还是作为另一个对象的成员变量被创建,它都存储在堆中。
下图说明了本地变量存储在线程栈,对象存储在堆中:
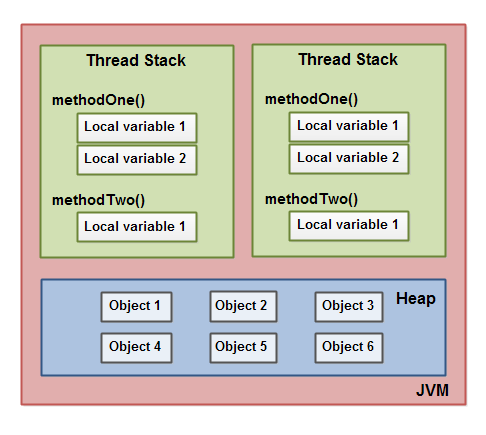
原始类型的本地变量存储在线程栈中,但如果本地变量是对象引用类型的话,对象引用存储在线程栈中,对象本身是存储在堆中。
一个对象可能包含方法,并且方法中可能包含本地变量。即使这个对象存储在堆中,这个对象包含的方法的本地变量也还是存储在线程栈中的。
对象的成员变量是存储在堆上的,不管成员变量是原始类型,还是引用类型都是存储在堆上。静态成员变量也同样是存储在堆上。
堆上的所有对象都可以被所有线程通过对象引用访问到。当线程进入一个对象后,它可以访问这个对象的成员变量。如果两个线程同时调用同一个对象的方法,他们都可以获取这个对象的成员变量,但每个线程都保存有这个对象方法的本地变量的副本,参考下图方便理解:
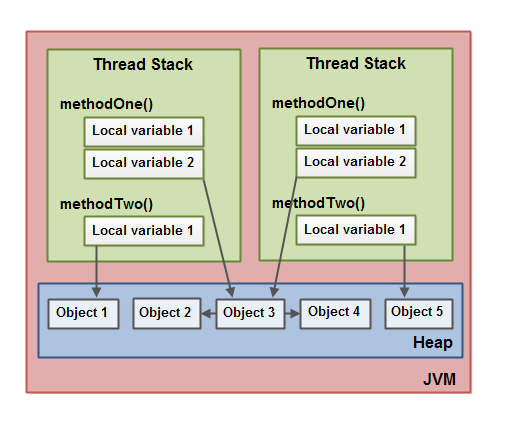
两个线程有一系列本地变量,其中一个本地变量 (Local Variable 2) 指向一个堆中的共享对象Object 3。这两个线程都保存有一个各自的对象引用指向同一个对象。他们引用是本地变量,并且存储在各自的线程栈中,这两个不同的引用指向堆中相同的变量。
注意,共享变量Object 3有引用指向成员变量Object 2和Object 4,两个线程可以通过共享变量的引用进入Object 2 和 Object 4。
上面图也展示了一个本地变量指向两个不同的堆对象。这里指向Object 1 和 Object 5两个不同的堆对象,理论上,如果两个线程都有两个对象的引用,都是可以进入Object 1 和 Object 5的。但是,上图显示的每个线程只能指向一个对象。
所以,怎么写程序才能导致上面的内存布局?如下:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41public class MyRunnable implements Runnable() {
public void run() {
methodOne();
}
public void methodOne() {
int localVariable1 = 45;
MySharedObject localVariable2 =
MySharedObject.sharedInstance;
//... do more with local variables.
methodTwo();
}
public void methodTwo() {
Integer localVariable1 = new Integer(99);
//... do more with local variable.
}
}
public class MySharedObject {
//static variable pointing to instance of MySharedObject
public static final MySharedObject sharedInstance =
new MySharedObject();
//member variables pointing to two objects on the heap
public Integer object2 = new Integer(22);
public Integer object4 = new Integer(44);
public long member1 = 12345;
public long member1 = 67890;
}
如果两个线程同时执行run()方法,就能展示出上图的内存布局。run()方法调用methodOne(),methodOne() 调用methodTwo()。
methodOne()声明一个本地原始类型变量(int localVariable1),和一个本地引用类型变量(MySharedObject localVariable2)。
每个线程执行methodOne方法都会在各自线程栈上创建localVariable1 和 localVariable2的副本。localVariable1在各自的线程栈上完全独立,一个线程对localVariable1的修改对另一个线程不可见。
每个线程执行methodOne将会创建各自的localVariable2副本。但是,两个localVariable2副本指向堆中的同一个对象。程序设置localVariable2指向一个静态变量,只有一个静态变量的副本,并且这个副本存储在堆中,所以,两个localVariable2的副本指向静态变量指向的同一个MySharedObject的实例,这个实例是存储在堆中的,这就像上面图标中的Object 3.
注意,MySharedObject类还有两个成员变量,他们和对象本身一起保存在堆中。这两个成员变量分别指向两个Integer类型的对象,这两个Integer对应上面图中的Object 2和Object 4
另外,methodTwo方法创建了一个本地变量localVariable1,这个变量是一个指向Integer类的对象引用。methodTwo设置本地变量localVariable1指向一个新的Integer实例,每个调用methodTwo的线程都保存一个localVariable1引用的副本。这两个Integer对象实例是保存在堆中的,但是,由于每次执行methodTwo都会创建一个Integer对象的实例,所以,两个线程执行methodTwo方法就创建了两个单独的Integer实例,这里在methodTwo方法内创建Integer对象对应上面图中Object 1 和Object 5。
还有一点需要注意,MySharedObject类中两个基本类型(long)的成员变量,由于他们是成员变量,所以,他们跟对象自身一个被存储在堆中。只有本地变量才存储在线程栈中。
二、计算机内存架构
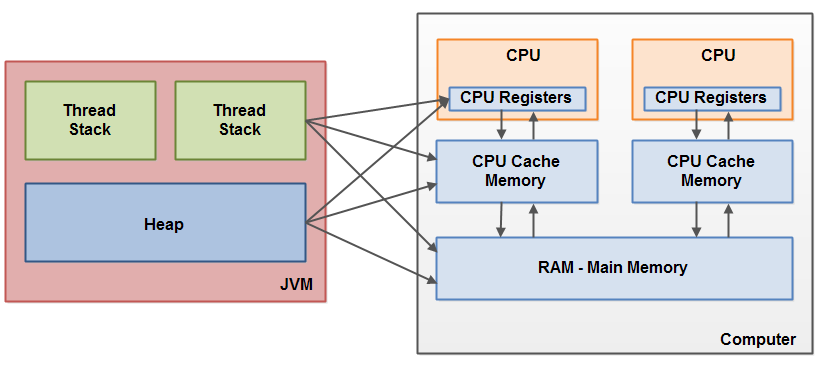
现代计算机内存架构跟Java内存模型有些不同。理解计算机内存架构以及Java内存模型怎么使用计算机内存非常重要,我们在这部分先介绍计算机内存架构,下一部分会介绍Java内存模型如果使用计算机内存。下图是计算机内存架构图:

现代计算机一般有2个或以上的CPU,有些CPU又是多核的。所以,有多个CPU的计算机可以支持多线程同时运行。每个CPU可以供一个线程执行,也就是说,如果Java应用是多线程的,那么每个CPU一个线程可以同时执行。
每个CPU中包含一些寄存器,这些寄存器本质上来说是CPU内部内存。由于CPU从寄存器获取数据比从主存获取数据快,所以,CPU在寄存器上执行命令比在计算机主存执行命令要快很多。
每个CPU有个缓存层,实际上,很多现代计算机都有不同大小的缓存层。CPU访问CPU缓存要比访问计算机主存快,但是没有访问内部寄存器快。所以,CPU缓存速度介于寄存器和计算机主存之间。有些CPU有多级缓存,但理解Java内存模型如何与计算机主存交换不是那么的重要,重要的是理解CPU有一个缓存层的概念。
计算机有个称为主存的区域(也就是RAM)。所有CPU都能进入主存,主存比CPU缓存要大很多。
当CPU需要访问主存时,一般从主存中读取一部分数据到CPU缓存中,再从CPU缓存中读取一部分到CPU寄存器中,然后执行指令。当CPU需要写数据到主存时,先将数据从CPU寄存器中刷到CPU缓存,然后再刷到主存中。
当CPU需要缓存其他数据到CPU缓存时,一般会将CPU缓存中现有的数据刷回主存中。CPU缓存每次可以写入一部分数据,刷回一部分数据到主存,没必要每次更新缓存中的所有数据。一般的,CPU缓存每次一个内存块,这个块被称为”cache lines”,通过“cache lines”完成主存和CPU缓存的数据交换。
三、缩小Java内存模型与计算机内存结构之间的差距
上面提到,Java内存模型不同于计算机内存结构。计算机内存结构不区分堆和栈。在计算机中,堆和栈可能都在主存中,部分堆和栈也可能在CPU内存和CPU寄存器中。如下图说明:
当对象和变量能够存储于计算机的不同内存区域,存在下面两个主要的问题:
- 多线程操作共享变量的可见性问题
- 操作共享变量的竞态条件
下面分别介绍这两个问题:共享变量可见性问题
如果在多线程间没有正确的使用volatile 或者 synchronization更新共享变量时,共享变量的最新值可能对其他线程不可见。
假设共享变量一开始存储在主存中,一个线程读取这个共享变量都线程所在的CPU缓存中,然后修改了这个共享变量,在CPU缓存没有刷回主存之前,修改后的最新值对其他线程是不可见的。每个线程在不同的CPU缓存中都有一份共享变量的副本。
下图说明了这个问题,一个线程在左边的CPU执行,复制一个共享变量的副本到左侧的CPU缓存中,并且修改count为2.但这个修改对右侧CPU中执行的线程不可见,因为对count的修改还没有刷回主存中。

要解决这个问题,可以使用volatile。volatile能够保证变量是直接从主存中读取的,并且修改会刷回主存中。
竞态条件
如果多线程同时修改共享变量就会出现竞态条件,假设A和B线程都读取共享变量var1到各自的CPU内存中,并且A和B线程都对var1.count共享变量加1,现在共享变量总共加了2次,每个CPU内存各加一次。
如果继续执行,变量count将增加2次,并刷回主存中,但是这些同时执行的加操作没有正确的同步执行。除非线程A和B都把更新count刷回主存。
下图说明了上面描述的竞态条件问题:
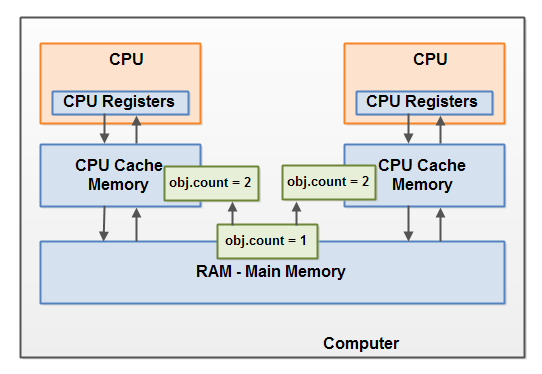
要解决这个问题,可以使用Java synchronized块。synchronized块保证任何时候只有一个线程可以进入相应的临界区,也能够保证在synchronized块中所有的变量都强制从主存中读取,并且对synchronized块中变量的更新都会刷回主存,不管这个变量是否声明为volatile。
