执行入口
入口程序在Scrapyd源代码的setup.py中指定:
Github - Scrapyd1
2
3
4setup_args['entry_points'] = {'console_scripts': [
# 打包后命令执行入口
'scrapyd = scrapyd.scripts.scrapyd_run:main'
]}
从代码可以看到,入口程序:scrapyd/scripts/scrapyd_run.py的main()函数;
1 | #!/usr/bin/env python |
这里是使用twistd命令,参数:【-n;-y】具体功能可以查看twistd -h查看,注释也写清楚了。
Twisted源码解析
最终执行的是twisted/scripts/twistd.py的run()方法;
1 | # -*- test-case-name: twisted.test.test_twistd -*- |
代码不多,直接贴上了。正如注释中所写,程序最终调用的是UnixApplicationRunner(Linux下)或者WindowsApplicationRunner(Windows下)的run()方法;
下面使用UnixApplicationRunner进行下面的流程。
1 | # 启动application |
这里createOrGetApplication()方法,就是用来加载前面scrapyd入口脚本中-y指定的txapp.py中的application的,这个到后面启动Service的时候,还会出现。
调用postApplication()启动应用和Twisted的事件循环;
1 | def postApplication(self): |
这里最终还是调用app.startApplication();
1 | def startApplication(application, save): |
到这个地方,一般正常使用Twisted的应用就是这么启动的。
具体怎么启动(startService)的?这块儿,我纠结的两天时间。
其实,这个地方的Twisted Application是个Componentized mixin,具体还得从上面我们指定的txapp.py看起。
1 | # scrapyd/txapp.py |
这个地方最终return的是scrapyd/app.py的Application;这才是Scrapyd的核心实现:
1 | from twisted.application.service import Application |
Scrapyd的核心实现
主要包括以3个主要服务:
- Launcher
- 主要功能是执行调度任务,从Poller中获取已经调度的任务并执行
- TCPServer
- 主要提供Web服务,通过Http接收请求。包括Job、Schedule、Logs等等
- TimerService
- 周期执行(5s),主要功能是从Web Server接收的调度任务中,每次每个project调度一个任务给Launcher执行
以及下面两个辅助的数据结构:
- Poller
- 对队列使用的一层抽象
- SqliteSpiderQueue
- 使用Sqlite作为队列底层存储的抽象
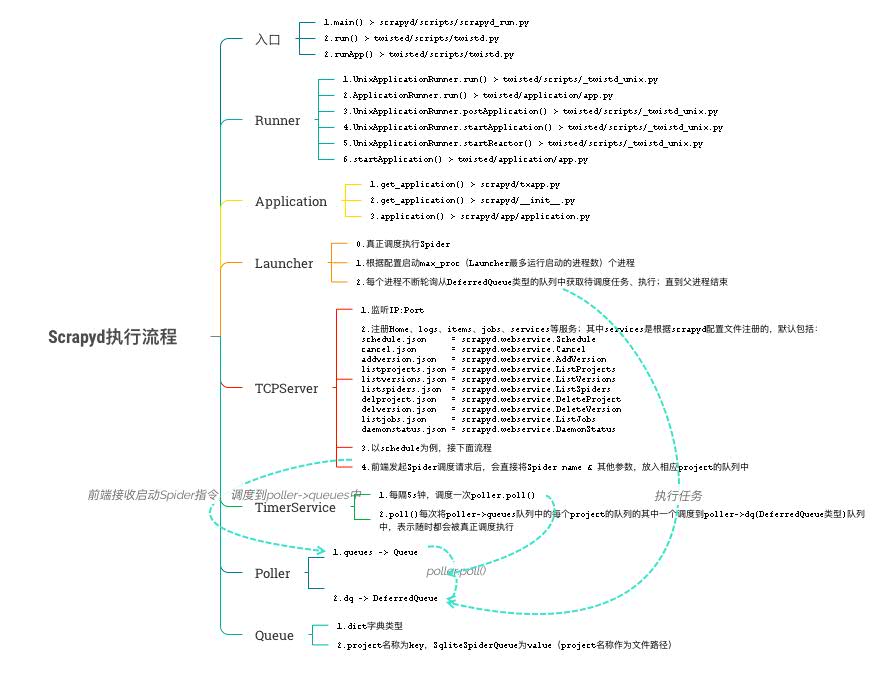
为了方便理解,看代码理解的时候总结了一张思维导图,如导图中所描述的,这样Scrapyd的三个核心服务,组成一个任务环,中间通过Poller和SqliteSpiderQueue两个辅助数据结构,实现类似生产者消费者模式。
这就是Scrapyd的核心实现,实现简单日志监控、任务调度、项目发布等基本功能接口。解决了Scrapy使用过程中的部分痛点。
由于Scrapyd使用还是面向程序员,管理控制台比较简陋且功能不完善,所以才有Gerapy出现了,可以在管理控制台上实现项目发布、启动Spider等等。但Gerapy做的也不太完善,比如周期性调度Spider等没有实现,可能在开发中。。。
