一、概念
Scrapyd是可以运行Scrapy爬虫的服务,允许我们部署Scrapy项目并且可以使用Http来控制爬虫。Scrapyd能够管理多个项目,并且每个项目可以有多个版本,但只有最新的版本才是有效的。
Scrapyd-client是Scrapyd的客户端,主要提供一种部署Scrapy项目到Scrapyd服务端的工具。
二、部署方式
开发环境部署Scrapyd-client1
pip install scrapyd-client
线上服务器部署Scrapyd1
pip install scrapyd
三、配置
Scrapyd安装完成后,在/etc/scrapyd目录下,生成配置文件scrapyd.conf,内容如下:
1 | [scrapyd] |
其中bind_address默认监听本地连接,可以修改成0.0.0.0在公网上访问,默认端口6800.
四、启动Scrapyd:
1 | nohup scrapyd |
之后就可以使用公网ip:6800访问了,这个是Scrapyd提供的一个简单监控页面。可通过此页面查看Spider、Log等相关信息。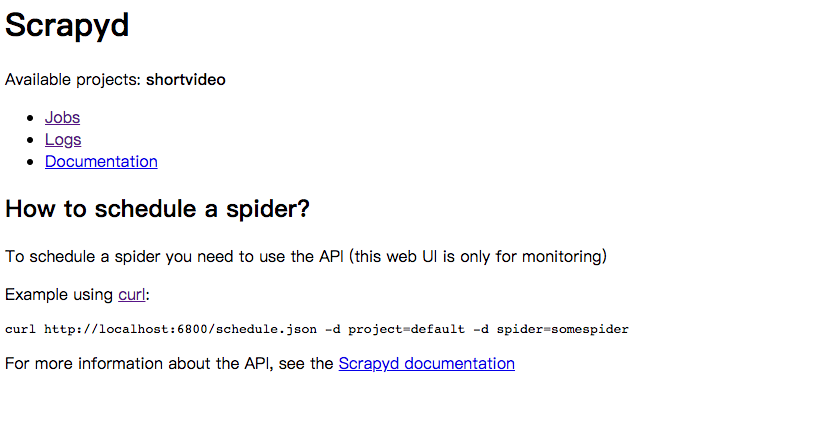
五、发布Spider
开发环境安装好Scrapyd-client后,就可以将开发好的Spider发布上线了。
首先需要将Scrapy项目中的scrapy.cfg修改下:
1 | [deploy:xxx] |
其中deploy:xxx代表Scrapyd服务端名称(可随意填写),url代表Scrapyd服务地址,project=xxx代表Scrapy项目名称
可以使用scrapyd-deploy -l检查配置是否正确,接下来关键的时候到了。
1 | scrapyd-deploy <target> -p <project> --version <version> |
将Spider打包发布到Scrapyd服务上,其中
六、启动Spider
Spider发布到Scrapyd服务端后,就可以在任何地方启动Spider的了,执行下面命令启动相应Spider:
1 | curl http://ip:port/schedule.json -d project=project_name -d spider=spider-name |
其中ip:port是Scrapyd服务地址,project_name是要启动的Spider所在项目名称,spider-name是要启动的Spider的名称。
七、停掉Spider
1 | curl http://ip:port/cancel.json -d project=project-name -d job=jobid |
其中jobid是要停止的Spider的jobid,可以在Scrapyd控制查看到
