云计算介绍
云计算是一种弹性的计算模式,以虚拟化为基础,以网络为中心,为用户提供安全、快速、便捷的数据存储和网络计算服务, 包括所需要的硬件、平台、软件及服务等资源,而提供资源的网络就被称为“云”。
达到让用户像使用水、电、煤气等资源一样便捷、高效。
服务类型:
- IaaS(基础设施即服务)
- PaaS(平台即服务)
- SaaS(软件即服务)
- FaaS(函数即服务)
阿里云计算
阿里云计算主要围绕下面几个方面提供服务
- 虚拟化
主要对应的阿里云产品是弹性计算,包括弹性计算服务ECS、弹性伸缩、容器服务、函数计算等等 - 存储&数据库
主要是分布式存储,包括块存储、文件存储、CDN、RDS、OceanBase等等 - 网络
包括负责均衡SLB、VPC、NAT网关、高速通道等等 - 安全
包括DDoS 基础防护、云防火墙、堡垒机等等 - 大数据应用及分析
MaxCompute、流计算、EMR、推荐引擎、机器学习、图像识别、自然语言处理等等 - 中间件
包括消息服务、日志服务、搜索服务、云服务总线CSB、应用配置管理等等 - 管理与工具
计费计量、云监控、资源编排、访问控制RAM等等
飞天开发平台
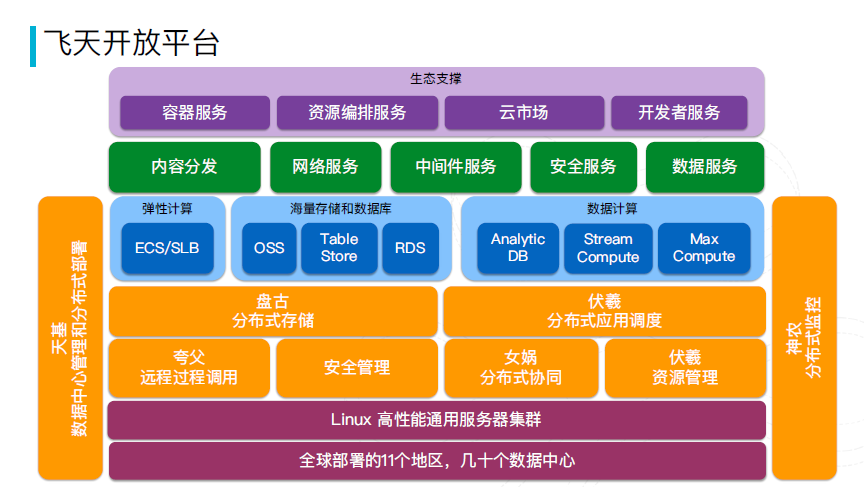
飞天—阿里云计算核心平台,支撑了阿里云弹性计算、中间件、网络、数据库、大数据存储、大数据计算等服务。
从设计图上可以看出,他包括盘古、伏羲、神农等等几个核心子系统。
我们今天主要介绍盘古分布式存储系统,和在他之上的产品(主要是表格存储)的设计和实现
分布式存储
定义:
使用大量普通 PC 服务器通过网络互联,对外作为一个整体提供存储服务。
存储的数据类型分类:
- 分布式文件系统
通常作为分布式表格、分布式数据库的底层存储;常见的AWS Dynamo,Google GFS等 - 分布式key-value系统
主要存储关系简单的半结构化数据,只提供基于主键的CRUD。是分布式表格的一种简化实现,一般用作缓存 - 分布式表格系统
阿里云的TableStore - 分布式数据库
阿里云OceanBase、HBase等
数据存储产品
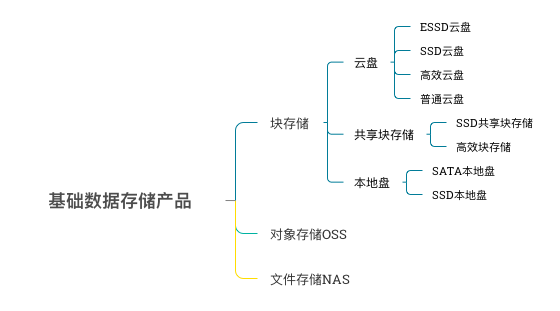
共享块存储支持将一个共享块存储挂载到多个ECS上,这个可以解决我们之前去重模块跟etl必须在一台机器上部署的问题。
目前在阿里云上大概有三种方式解决:
- 1.通过共享块存储
- 2.通过NAS
- 3.通过云存储网关,本质上是通过NFS协议使用OSS来实现
弹性块存储EBS
弹性块存储是阿里云为ECS云服务器提供的块设备,高性能、低时延,满足随机读写,可以像使用物理硬盘一样格式化、创建文件系统。可用于大部分通用业务场景下的数据存储。
主要产品:各种云盘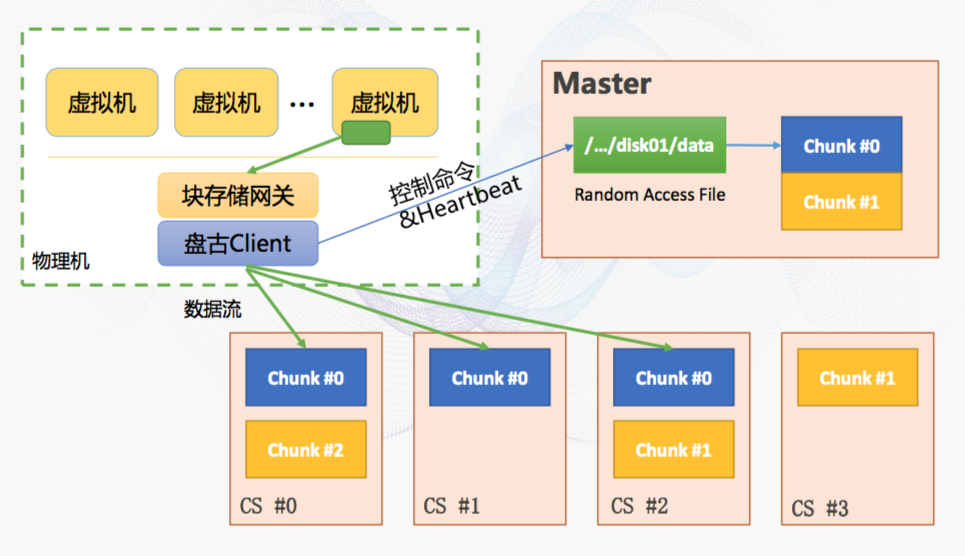
从设计图上可以看出EBS是在盘古的基础上开发了一个块存储网关。
块存储网关主要功能:
- 一是负责磁盘虚拟化:将后端盘古存储空间映射为本地盘(我们在阿里云上使用的ECS,是通过虚拟化的方式使用宿主机的cpu、内存、存储等等,这个有兴趣的话可以研究下)
- 二是存储协议转换:IO请求转发到盘古Client
表格存储TableStore
表格存储是构建在阿里云飞天分布式系统之上的 NoSQL 数据存储服务,提供海量结构化数据的存储和实时访问。
表格存储以实例和表的形式组织数据,通过数据分片和负载均衡,达到规模的无缝扩展。
表格存储向应用程序屏蔽底层硬件平台的故障和错误,能自动从各类错误中快速恢复,提供非常高的服务可用性。
表格存储管理的数据全部存储在 SSD 中并具有多个备份,提供了快速的访问性能和极高的数据可靠性。
表格存储核心竞争力
- 大数据模型
- 分布式 + LSM(Log Structured Merge Trees)存储引擎:水平扩展,海量存储,高吞吐写入能力
- 动态负载均衡,热点快速迁移
- 自动连续分裂
- 读写性能不受并发及数据存储规模影响
- 数据生命周期
- 完善的数据通道
- 离线全量通道(CDP):对接离线计算引擎,数据分层
- 实时增量通道(DTS):对接实时计算或搜索引擎,增量同步
- 存储与计算结合
- 打通在线存储、离线计算和实时分析的数据闭环
- 容灾
- 同城双集群、两地三中心和单元化
- 成本优化
- 计算成本:按量付费,资源包
- 存储成本:低存储成本容量型实例,分级存储,优化压缩
表格存储系统架构
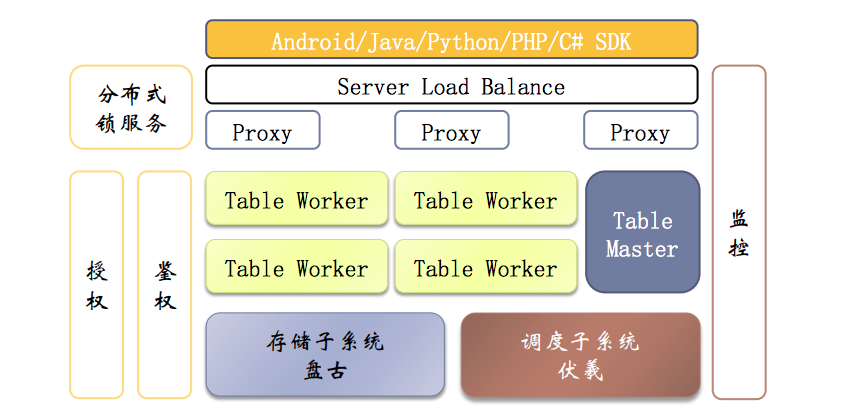
首先是用户层,我们使用的SDK,系统将用户使用SDK的请求通过SLB分发到多个Proxy(其实是内部的Client)上,这里实现Proxy的高可用。
然后Proxy与TableMaster和TableWorker交互,完成用户请求。
TableMaster和TableWorker、盘古、伏羲后面会有介绍
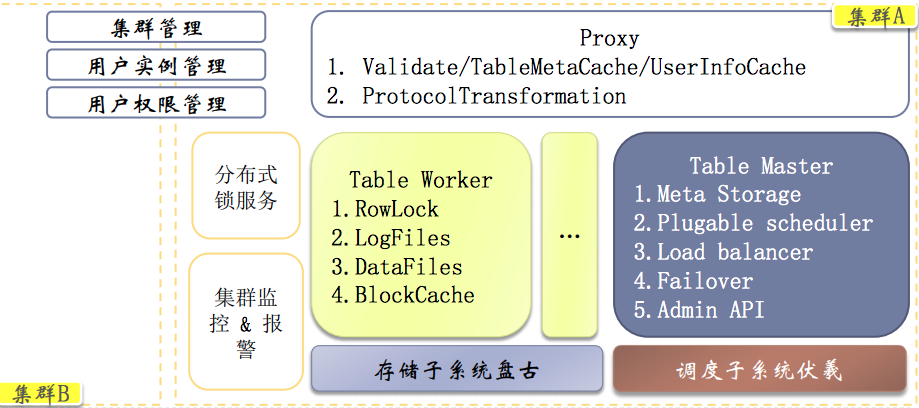
- Proxy:负责鉴权及Meta数据缓存,协议转换等
- Master:
负责表级的元数据管理,建表、删表;分片的调度;自动的分片、负载均衡(将不同分片调度到空闲的TableWorker来加载);容错等 - Table Worker:
主要负责分区数据加载,读写数据、行锁等。为了提高性能,内部也会维护一个缓存(这个后面会介绍)
接着是存储子系统盘古和调度子系统伏羲:
- 1.表格存储的数据实际是在盘古,由盘古来提供数据的可靠存储,后面有盘古的介绍,这里不展开。
- 2.调度子系统伏羲 配合TableMaster做调度,伏羲知道集群中机器的负载情况,协助TableMaster做调度。
从这个图可以看出表格存储&盘古的整体设计有点类似ceph的设计,TableMaster和盘古可独立扩展。
表格存储高可用—Failover
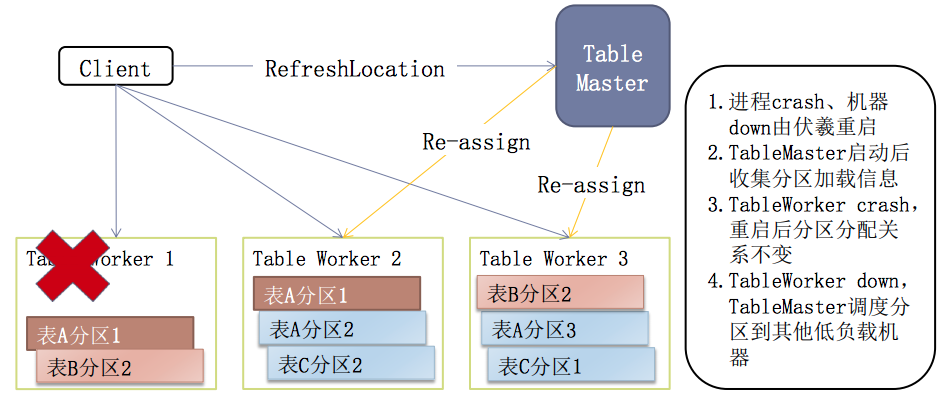
Master Failover:
由于表格存储的元数据是存储在盘古上的,所以数据容量 原则上是没有限制的(扩展性问题)。也由于盘古提供的可靠共享存储,表格存储的Master可以做到无状态,这样就比较容易的实现高可用。
从这个图上可以看出,Master进程Crash或者机器宕机是由伏羲负责拉起,然后收集分区加载信息,但这样可能会有一段时间的不可用(咨询了表格存储的技术支持,可能是在对外的资料中隐藏了一些技术细节,但他说的小集群3个Master,大集群5个Master,在加上使用的是盘古共享存储,猜测这里应该跟HDFS的NameNode一样,使用zookeeper选主实现Master高可用)。
Table Worker Failover:
由于元数据存储在盘古上,所以当Table Worker宕掉后,分区可以直接由新的Table Worker来加载
表格存储高性能-自动连续分裂
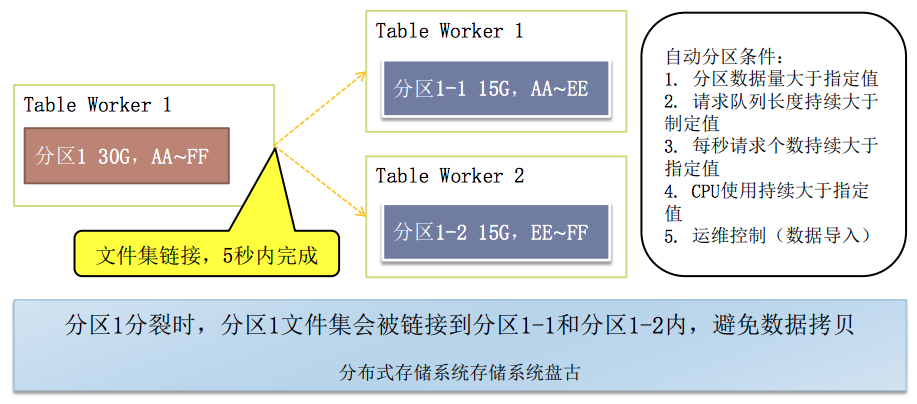
1.表格存储支持连续的自动分裂(也是一种负责均衡的实现)。
由于表格存储使用第一个主键列分片,而且数据是按主键列排序的,所以在当分片过大或者过热时可以很容易的分片,再加上表格存储的数据分区是逻辑单位,实际的数据存储在盘古(共享存储的好处),所以在分裂时,不需要迁移数据,可以很快完成分裂。2.由于表格存储是基于LSM(Log Structured Merge Trees)的,在数据写入或者更新的时候,会先写入commitlog进行持久化,然后再写入内存中的MemTable,MemTable会定期的flush成一个新的数据文件,后台定期对不同的数据文件进行合并,合并为一个更大的数据文件,并清理垃圾数据等。
3.表格存储一张表的每个分片都拥有独立的commitlog,每次修改的内容都会append写入commitlog。当节点故障时,内存中的MemTable还未flush成数据文件,此时发生failover,分片被另外的TableWorker加载,只需要重新replay一部分commitlog即可恢复MemTable,保证写入的数据不丢。
分布式存储系统-盘古
- 高可靠
- 多副本强一致
- 端到端的数据校验、静默错误的检查
- 高可用
- 多租户隔离
- 基于Paxos的多组Master
- Federation支持水平扩展
- 高性能
- 混合存储:SSD作为SATA盘Cache
- 内存零拷贝
- 数据处理流水线化增大吞吐
- 低成本
- 集群间共享数据
- EC(Erasure Coding)等
盘古架构
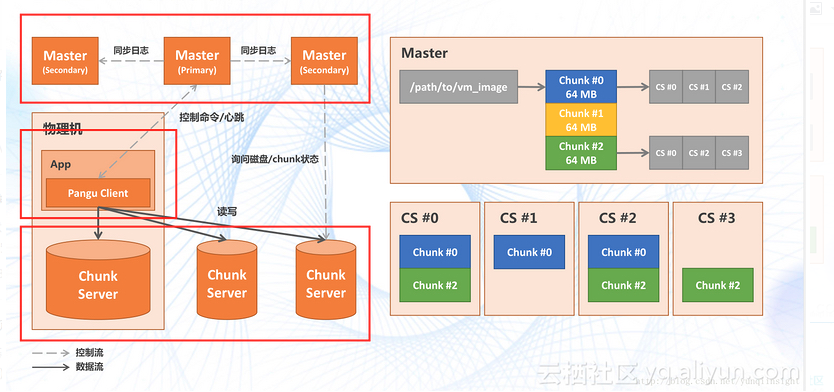
三个模块:Master、Client、Chunk Server
了解HDFS实现的人应该很熟悉这个图,盘古同HDFS一样采用(主从)master/slave设计。一个存储集群是由一组Master和一定数目的Chunk Server组成,在数据读写时Client先请求Master获取到数据存储的元数据,之后的数据读写,Client就直接跟Chunk Server交互了。Chunk Server和Master保持心跳,向Master反馈数据状态以及接受Master的指令。大部分的分布式存储系统设计都差不多,其中OpenStack的Ceph区别较大,代表了分布式块存储设计的方向。
为了好理解,这里引用的是盘古1.0的设计图,盘古2.0主要的变化主要是Master节点在高可用上变化。
盘古Master
对应HDFS的NameNode,负责元数据管理,最主要的就是维护两个映射关系:
- 文件名到数据块;
- 数据块到Chunk Server列表。
其中文件名到数据块的信息保存在磁盘上(持久化);但Master不保存数据块到Chunk Server列表,这个是通过Chunk Server在启动时的上报数据块信息,更新Master上的映射表。
Master暴露了文件系统的名字空间,用户可以 以文件的形式在上面存储数据。
Master在分布式文件系统中需要解决的三个核心问题:
- 容量以Federation方式水平扩展
- 高效数据流量动态规划实现最大吞吐
- 高可用:Paxos数据一致,防止单点
盘古Chunk Server
对应HDFS的DataNode,负责数据存储,一般是多台组成集群。
存储过程中,一个文件被分成一个或多个数据块(至少一个),这些块存储在多个Chunk Server上,每块数据通过多副本来保证可靠性以及加快后期的读取速度。Chunk Server负责处理分布式文件系统客户端的实际的读写数据请求。在Master的统一调度下进行数据块的创建、删除和复制。
- 三副本强一致
三副本位于不同的故障域(rack),故障时自动多点数据复制 - 端到端的数据校验,静默错误检查
- 心跳
与Master维护心跳,上报机器状态;接收Master指令; - 混合存储提高写入性能、EC降低存储成本
Master扩展性
可扩展: 不成为系统瓶颈,能随数据服务器数量的增多而线性扩展
- 元数据的容量不成为系统瓶颈
- 服务请求能力不成为系统瓶颈
常用的实现方式:
- Federation
盘古Master扩展性-Federation
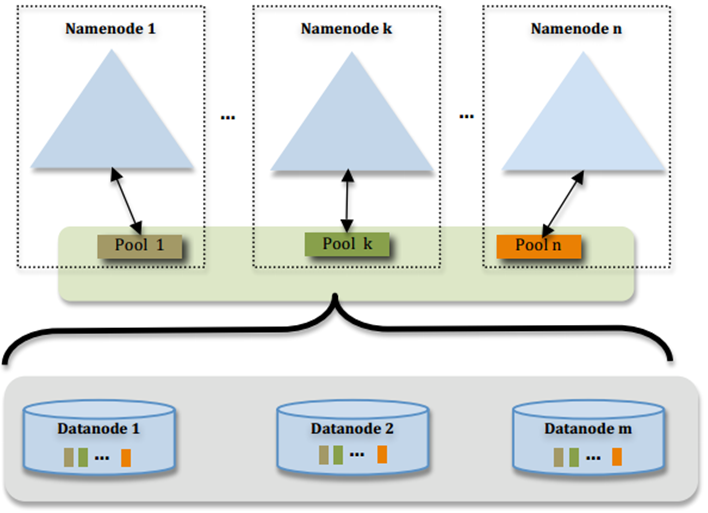
跟HDFS一样,基于Federation实现Master水平扩展。
Federation使用了多个独立的Namespace,namenode之间相互独立且不需要互相协调,各自分工,管理自己的区域。
分布式的datanode被用作通用的数据块存储存储设备。每个datanode要向集群中所有的namenode注册,且周期性地向所有namenode发送心跳和块报告,并执行来自所有namenode的命令。
一个block pool由属于同一个namespace的数据块组成,每个datanode可能会存储集群中所有block pool的数据块。每个block pool内部自治,也就是说各自管理各自的block,不会与其他block pool交流。一个namenode挂掉了,不会影响其他namenode。
某个namenode上的namespace和它对应的block pool一起被称为namespace volume(命名空间卷)。它是管理的基本单位。当一个namenode/nodespace被删除后,其所有datanode上对应的block pool也会被删除。当集群升级时,每个namespace volume作为一个基本单元进行升级。
高可用实现方式
高可用 :不成为故障单点
- 多个备份,故障时快速切换
- 保证状态一致性
常用的实现方式:
- 主从同步
- 分布式协议
高可用实现方式-主从模式
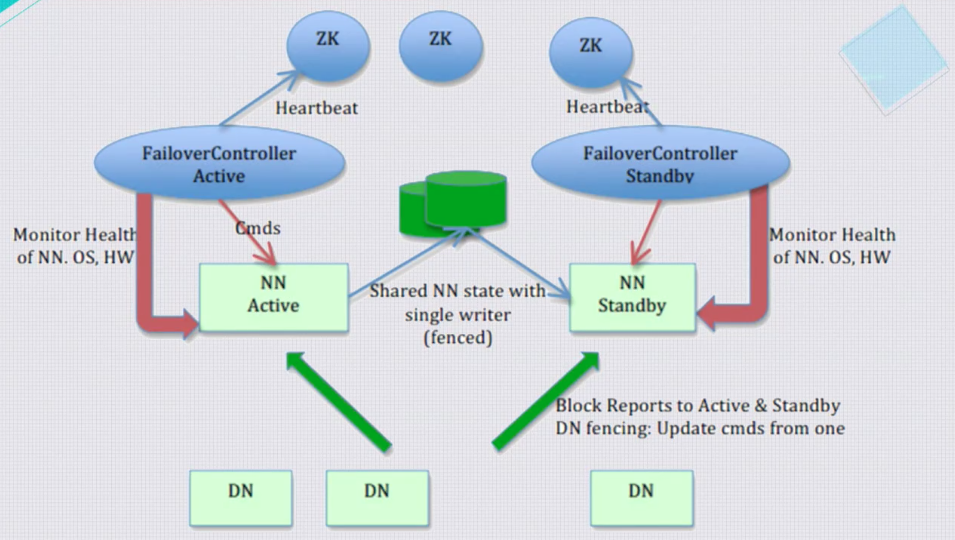
HDFS的实现方式,
- 1)分布式锁互斥实现选主(ZK)
- 2)通过共享存储实现数据一致性,HDFS是使用NFS作为共享存储
- 3)通过心跳检测故障
盘古Master高可用实现方式-分布式协议
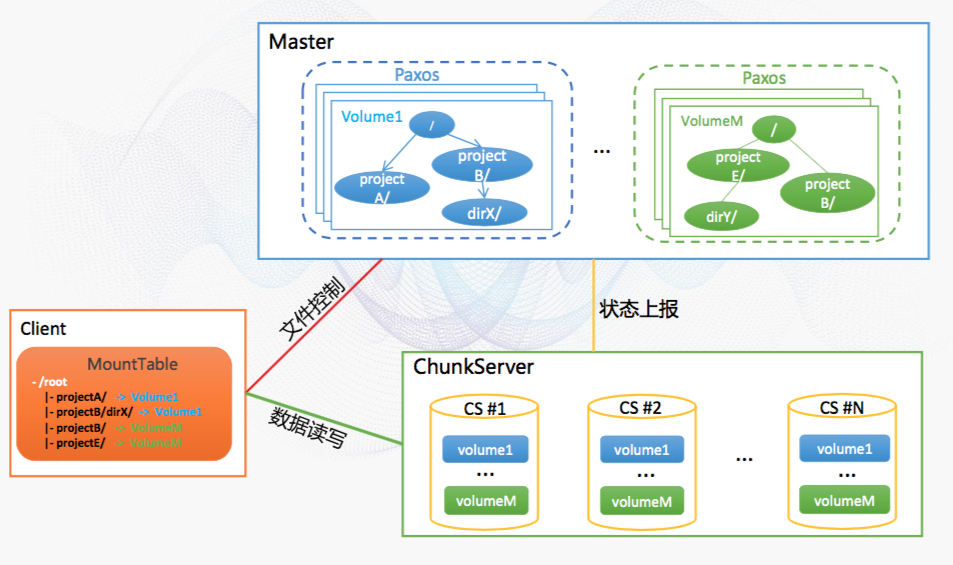
- 1)使用Paxos一致性协商协议,保证高可用和快速切换
- 2)不依赖外部共享存储和互斥锁服务,独立自包含
其实,了解到盘古是基于Raft协议实现的类Paxos协议。现在很多公司的分布式存储都采用Raft协议实现一致性,感兴趣的可以研究下。
Master高性能,通过使用Raid卡(或者闪存),提高Meta的读写性能。
由于raid卡是带cache,并且是有电池的,所以在掉电的情况下可以电池放电周期内不丢失数据,所以,master可以在写入raid卡后就返回客户端成功,后台离线将缓存中的数据刷入后端SATA硬盘中。
